
Python 파이썬으로 네이버 오픈 API 사용법 : 네이버 기사 크롤링 Crawling 하기
참고 문헌 : IT CookBook, 데이터 과학 기반의 파이썬 빅데이터 분석(이지영), 네이버api 문서 ]
소스코드는 참고 문헌을 통해 가져왔습니다.
Python 파이썬으로 네이버 오픈 API 사용법 | 네이버 기사 크롤링 Crawling 하기
Python 파이썬을 통해 네이버 뉴스 기사 정보를 가져올 수 있습니다.
1. 네이버 개발자 센터 들어가고 오픈API 권한 신청
우선 네이버 아이디가 필요합니다. 네이버 개발자센터를 검색하고 들어갑니다.
링크 올려두겠습니다. https://developers.naver.com/main/
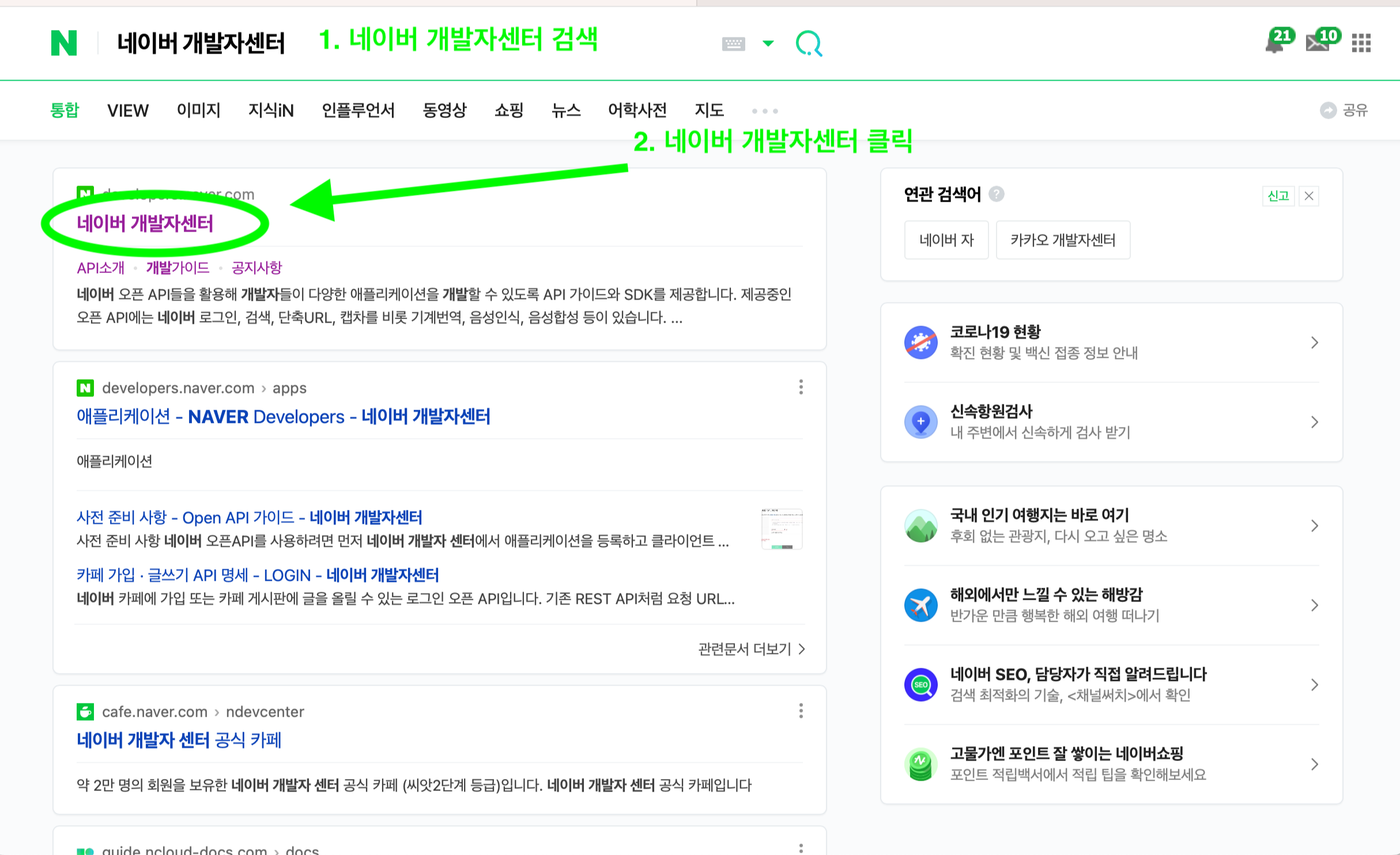
네이버 로그인을 해주고 서비스 API클릭
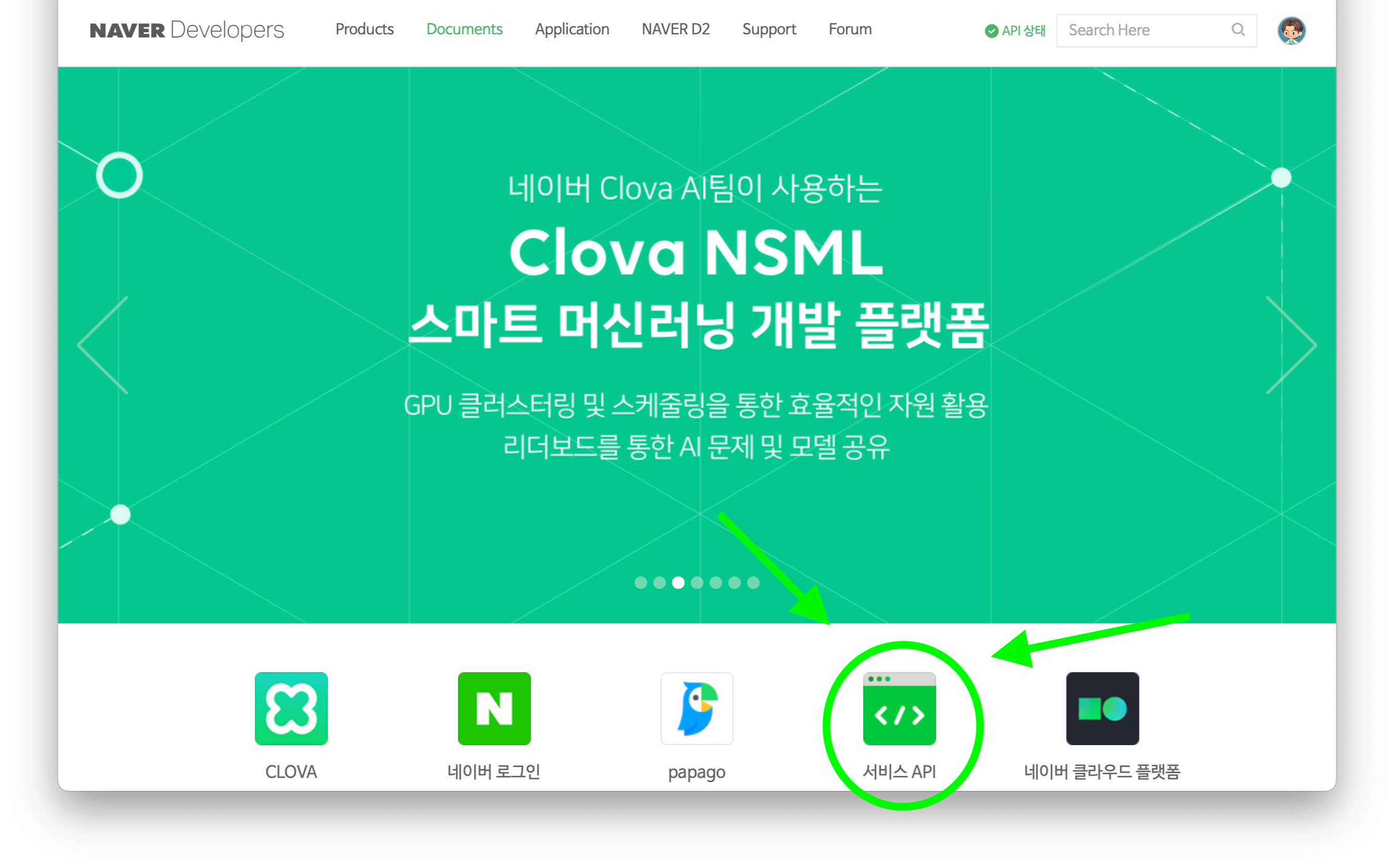
개발자센터에 들어간 후 서비스 API에 들어가줍니다.
그런 다음 애플리케이션 등록을 해줍니다.
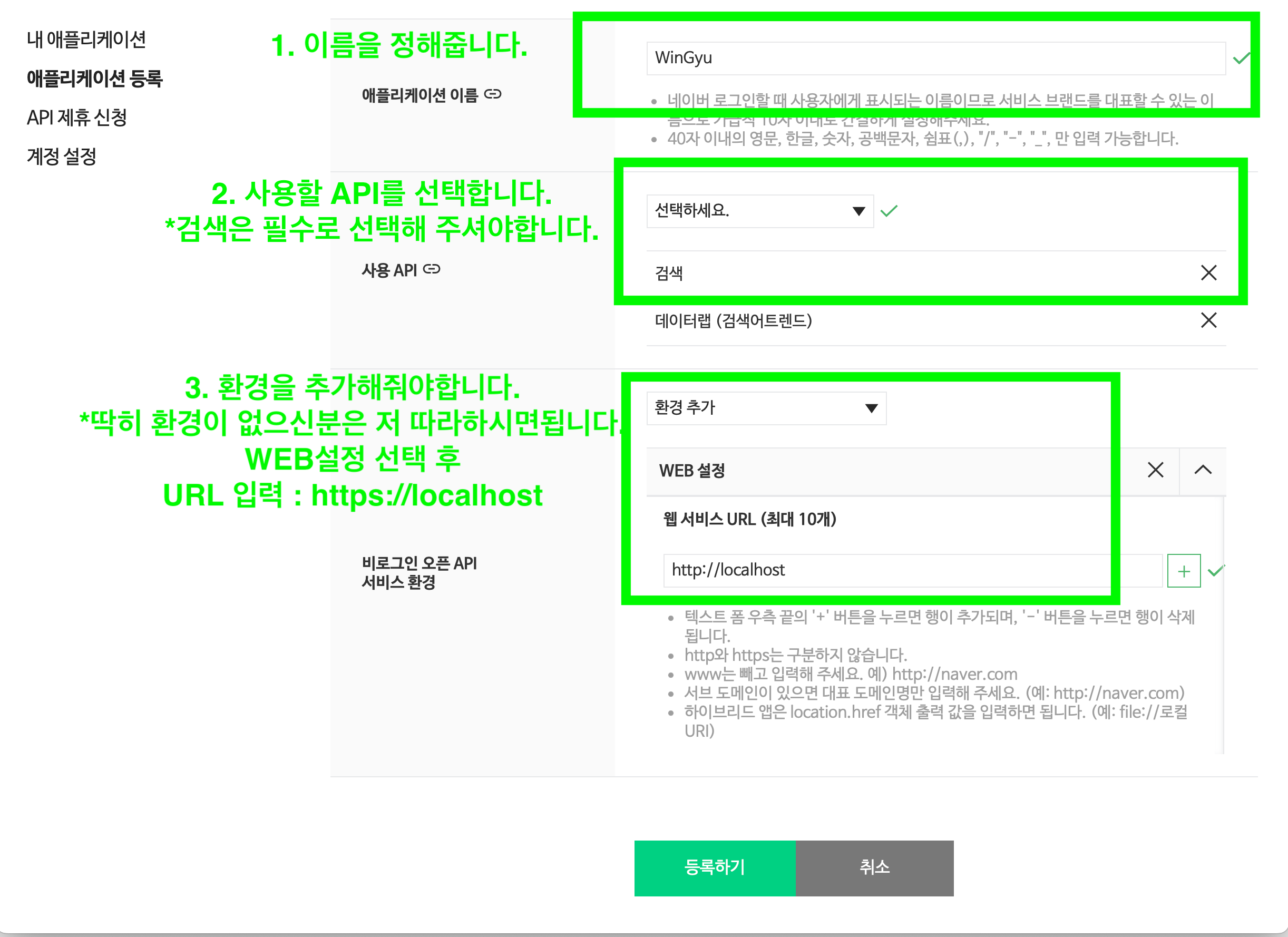
전부 작성하시면 등록하기 버튼을 눌러줍니다.
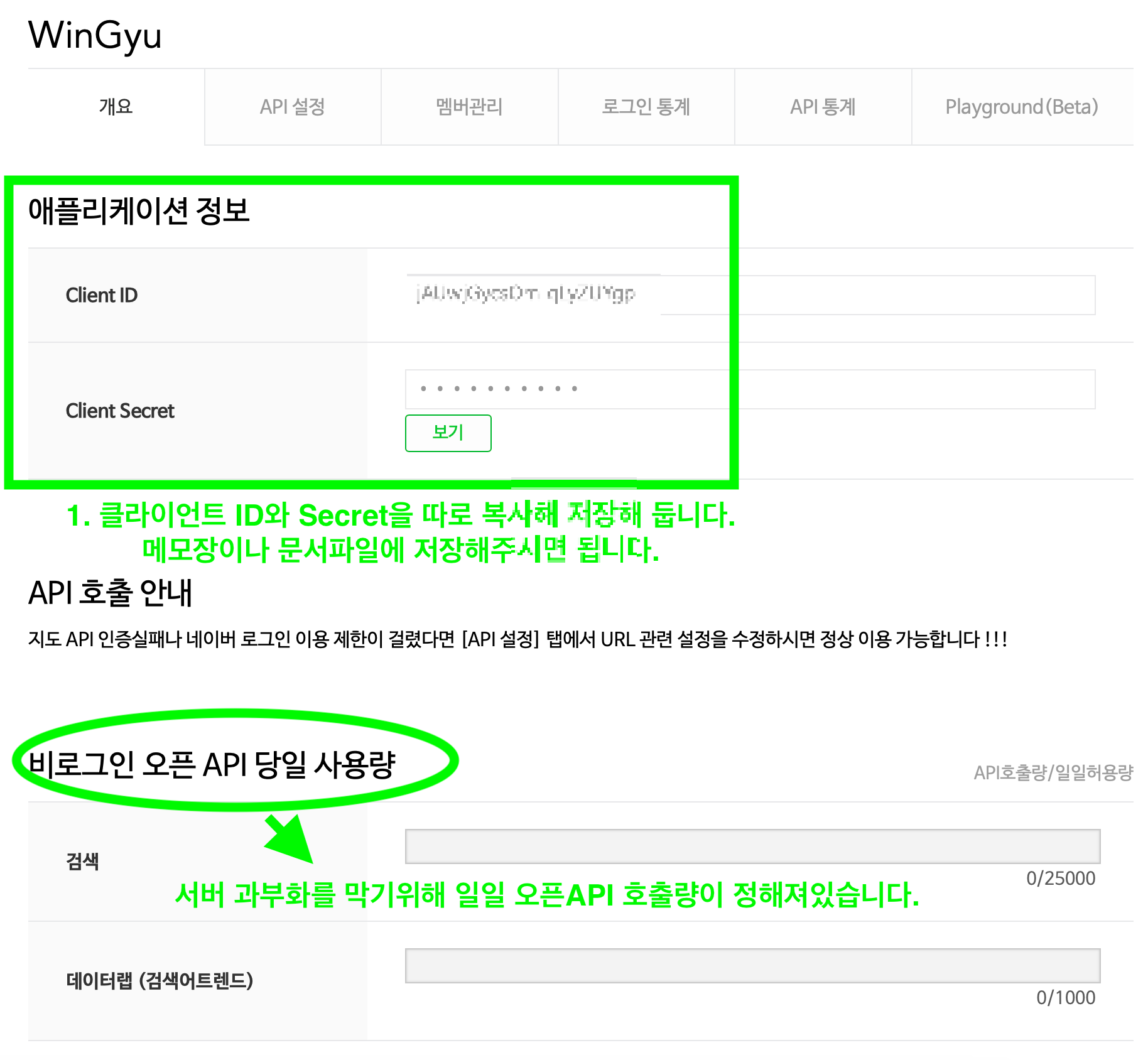
등록 완료하시면 Client ID, Client Secret를 복사해 둡니다.
#아래에 있는 당일 사용량은 말 그대로 일일 사용량이 정해져있습니다.
복사완료 하였으면 1단계 완료입니다.
2. Python 파이썬으로 네이버 뉴스 크롤링 소스 코드
import os
import sys
import urllib.request
import datetime
import time
import json
client_id = "아이디"
client_secret = "시크릿"
각종 필요한 모듈 및 변수입니다.
client_id, client_secret 아이디, 시크릿 부분에 아까 복사해둔 코드를 붙여넣습니다.
# [CODE 1]
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
1번째 소스코드 입니다. url를 받고 요청하는 함수입니다.
req = urllib.request.Request(url) req.add_header(“X-Naver-Client-Id”, client_id) req.add_header(“X-Naver-Client-Secret”, client_secret)
urllib.request 함수를 통해 url을 받고
클라이언트 아이디 및 시크릿을 입력 받습니다.
그후 아래 try: except코드입니다. #try 및 except 함수는 차후에 설명해드리겠습니다.
요청을 성공할시 요청을 보낸 시간을 프린트합니다.
실패할시 에러가 난 url과 실패한 시간을 프린트합니다.
# [CODE 2]
def getNaverSearch(node, srcText, start, display):
base = "https://openapi.naver.com/v1/search"
node = "/%s.json" % node
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(srcText), start, display)
url = base + node + parameters
responseDecode = getRequestUrl(url) # [CODE 1]
if (responseDecode == None):
return None
else:
return json.loads(responseDecode)
2번째 소스코드 입니다.
코드1에 보낼 url을 제작합니다.
base = "https://openapi.naver.com/v1/search"
open api주소에 접속 후
node = "/%s.json" % node
받을 파일 형식을 정합니다. json외에 다른 파일로 받을 수 있습니다. #json이 인기가 가장 많습니다.
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(srcText), start, display)
url = base + node + parameters
responseDecode = getRequestUrl(url) # [CODE 1]
if (responseDecode == None):
return None
else:
return json.loads(responseDecode)
url 에 마지막 파라미터를 받고 url주소를 완성합니다.
url = base + node + parameters
responseDecode = getRequestUrl(url) # [CODE 1]
완성된 주소를 소스코드 1에 보내고 그 값을 변수에 저장합니다.
# [CODE 3]
def getPostData(post, jsonResult, cnt):
title = post['title']
description = post['description']
org_link = post['originallink']
link = post['link']
pDate = datetime.datetime.strptime(post['pubDate'], '%a, %d %b %Y %H:%M:%S +0900')
pDate = pDate.strftime('%Y-%m-%d %H:%M:%S')
jsonResult.append({'cnt': cnt, 'title': title, 'description': description,
'org_link': org_link, 'link': org_link, 'pDate': pDate})
return
3번째 소스코드 입니다.
title = post['title']
description = post['description']
org_link = post['originallink']
link = post['link']
받고싶은 정보를 변수값에 저장합니다.
title = 뉴스 제목
description = 메인 내용
org_link = 뉴스 페이지 원본(오리지널) 링크
link = 뉴스 페이지 링크
pDate = datetime.datetime.strptime(post['pubDate'], '%a, %d %b %Y %H:%M:%S +0900')
pDate = pDate.strftime('%Y-%m-%d %H:%M:%S')
jsonResult.append({'cnt': cnt, 'title': title, 'description': description,
'org_link': org_link, 'link': org_link, 'pDate': pDate})
return
시간 데이터 및 위에 끌어온 모든 정보들을 최종 결과값인 jsonResult에 append 추가해 줍니다. #추후에 append함수 설명
# [CODE 0]
def main():
node = 'news' # 크롤링 할 대상
srcText = input('검색어를 입력하세요: ')
cnt = 0
jsonResult = []
jsonResponse = getNaverSearch(node, srcText, 1, 100) # [CODE 2]
total = jsonResponse['total']
while ((jsonResponse != None) and (jsonResponse['display'] != 0)):
for post in jsonResponse['items']:
cnt += 1
getPostData(post, jsonResult, cnt) # [CODE 3]
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100) # [CODE 2]
print('전체 검색 : %d 건' % total)
with open('%s_naver_%s.json' % (srcText, node), 'w', encoding='utf8') as outfile:
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
outfile.write(jsonFile)
print("가져온 데이터 : %d 건" % (cnt))
print('%s_naver_%s.json SAVED' % (srcText, node))
if __name__ == '__main__':
main()
마지막 소스코드입니다.
node = 'news' # 크롤링 할 대상
srcText = input('검색어를 입력하세요: ')
cnt = 0
jsonResult = []
node는 무엇을 크롤링할지 결정하는 변수입니다.
검색어를 입력받고
jsonResult는 위에 모든 데이터들을 받는 리스트 입니다.
jsonResponse = getNaverSearch(node, srcText, 1, 100) # [CODE 2]
total = jsonResponse['total']
몇개의 데이터를 받아올지 정하는 코드입니다. 1, 100을 적으면 100개의 뉴스 데이터를 끌어옵니다.
total = 몇개의 데이터를 불러왔는지 받는 변수입니다.
while ((jsonResponse != None) and (jsonResponse['display'] != 0)):
for post in jsonResponse['items']:
cnt += 1
getPostData(post, jsonResult, cnt) # [CODE 3]
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100) # [CODE 2]
데이터를 하나씩 계속 받는 반복문입니다. #while은 추후에 설명
while ((jsonResponse != None) and (jsonResponse['display'] != 0)):
이 뜻은 크롤링할때 정보가 None값, 데이터가 없거나 display != 0 검색 결과가 없는경우 크롤링을 실행하지 않습니다.
아래 반복되는것은 정보들을 받는 코드입니다.
print('전체 검색 : %d 건' % total)
with open('%s_naver_%s.json' % (srcText, node), 'w', encoding='utf8') as outfile:
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
outfile.write(jsonFile)
print("가져온 데이터 : %d 건" % (cnt))
print('%s_naver_%s.json SAVED' % (srcText, node))
전체 검색 수 프린터 된후
with open 함수를 통해 파일을 작성합니다. encoding=’utf-8’이 코드가 없을시 문자가 깨지는 오류가 발생합니다.
if __name__ == '__main__':
main()
이 코드는 이 파일을 실행시키는곳이 이 파일이랑 동일시할때 실행하는 코드입니다.
이 코드는 이 파일을 실행시키는곳이 이 파일이랑 동일시할때 실행하는 코드입니다.
코드 실행후 월드컵을 입력했을때 결과입니다.
[
{
"cnt": 1,
"description": "캐러거는 2022 카타르 <b>월드컵</b> 시기에 대해 분노했다. 'CBS스포츠'를 통해 "카타르에 <b>월드컵</b> 개최권을 내준 것부터 잘못됐다. 여름에 열겠다고 했지만 기온 때문에 불가능했고 결국 시즌을 한창 치를 때로 옮겨야하는... ",
"link": "http://www.footballist.co.kr/news/articleView.html?idxno=157822",
"org_link": "http://www.footballist.co.kr/news/articleView.html?idxno=157822",
"pDate": "2022-11-02 15:28:53",
"title": "손흥민 부상에 분노, 캐러거 "평생 <b>월드컵</b> 꿈꾸던 선수가…""
},
{
"cnt": 2,
"description": "카타르<b>월드컵</b>까지는 스티브 데이비스 감독대행 체제로 간다. 로페테기 감독은 지난 10월 세비야에서 경질됐다. 울버햄튼은 무적 상태인 로페테기 감독과 계약이 체결되기를 바랐지만 개인적인 사유로 인해... ",
"link": "http://www.sisafocus.co.kr/news/articleView.html?idxno=285990",
"org_link": "http://www.sisafocus.co.kr/news/articleView.html?idxno=285990",
"pDate": "2022-11-02 15:28:53",
"title": "'강등권' 울버햄튼, 거절했던 훌렌 로페테기 감독 다시 러브콜… 사전협상"
},
코드 실행 후 월드컵을 입력하니 월드컵 json파일이 생성되었습니다.
이로서 Python 파이썬을 통해 오픈 api를 사용해서 네이버 뉴스를 가져와봤습니다.
추후에 오픈 api말고 다른 방법으로 크롤링 해보겠습니다.
전체 소스 코드입니다.
import os
import sys
import urllib.request
import datetime
import time
import json
client_id = "클라이언트 아이디"
client_secret = "시크릿 코드"
# [CODE 1]
def getRequestUrl(url):
req = urllib.request.Request(url)
req.add_header("X-Naver-Client-Id", client_id)
req.add_header("X-Naver-Client-Secret", client_secret)
try:
response = urllib.request.urlopen(req)
if response.getcode() == 200:
print("[%s] Url Request Success" % datetime.datetime.now())
return response.read().decode('utf-8')
except Exception as e:
print(e)
print("[%s] Error for URL : %s" % (datetime.datetime.now(), url))
return None
# [CODE 2]
def getNaverSearch(node, srcText, start, display):
base = "https://openapi.naver.com/v1/search"
node = "/%s.json" % node
parameters = "?query=%s&start=%s&display=%s" % (urllib.parse.quote(srcText), start, display)
url = base + node + parameters
responseDecode = getRequestUrl(url) # [CODE 1]
if (responseDecode == None):
return None
else:
return json.loads(responseDecode)
# [CODE 3]
def getPostData(post, jsonResult, cnt):
title = post['title']
description = post['description']
org_link = post['originallink']
link = post['link']
pDate = datetime.datetime.strptime(post['pubDate'], '%a, %d %b %Y %H:%M:%S +0900')
pDate = pDate.strftime('%Y-%m-%d %H:%M:%S')
jsonResult.append({'cnt': cnt, 'title': title, 'description': description,
'org_link': org_link, 'link': org_link, 'pDate': pDate})
return
# [CODE 0]
def main():
node = 'news' # 크롤링 할 대상
srcText = input('검색어를 입력하세요: ')
cnt = 0
jsonResult = []
jsonResponse = getNaverSearch(node, srcText, 1, 100) # [CODE 2]
total = jsonResponse['total']
while ((jsonResponse != None) and (jsonResponse['display'] != 0)):
for post in jsonResponse['items']:
cnt += 1
getPostData(post, jsonResult, cnt) # [CODE 3]
start = jsonResponse['start'] + jsonResponse['display']
jsonResponse = getNaverSearch(node, srcText, start, 100) # [CODE 2]
print('전체 검색 : %d 건' % total)
with open('%s_naver_%s.json' % (srcText, node), 'w', encoding='utf8') as outfile:
jsonFile = json.dumps(jsonResult, indent=4, sort_keys=True, ensure_ascii=False)
outfile.write(jsonFile)
print("가져온 데이터 : %d 건" % (cnt))
print('%s_naver_%s.json SAVED' % (srcText, node))
if __name__ == '__main__':
main()
감사합니다
댓글남기기